
智谱AI CEO张鹏:担心Scaling Law碰到天花板,为时过早
智谱AI CEO张鹏:担心Scaling Law碰到天花板,为时过早环境持续变化,时代总在迭变,“商业之王”们紧随时代浪潮,坚持创造,谋求新动能。立足中国经济大转型的当下,WISE2024 商业之王大会,一同发现真正有韧性的“商业之王”,探寻中国商业浪潮里“正确的事”。
来自主题: AI资讯
7592 点击 2024-11-30 16:03
 搜索
搜索
环境持续变化,时代总在迭变,“商业之王”们紧随时代浪潮,坚持创造,谋求新动能。立足中国经济大转型的当下,WISE2024 商业之王大会,一同发现真正有韧性的“商业之王”,探寻中国商业浪潮里“正确的事”。
什么?Scaling Law最早是百度2017年提的?! Meta研究员翻出经典论文: 大多数人可能不知道,Scaling law原始研究来自2017年的百度,而非三年后(2020年)的OpenAI。

随着scaling law撞墙新闻爆出,全球科技圈、资本市场关于大模型发展触及天花板的讨论愈演愈烈。那么,AI发展是否放缓?后续又将如何发展?商业模式如何突破?

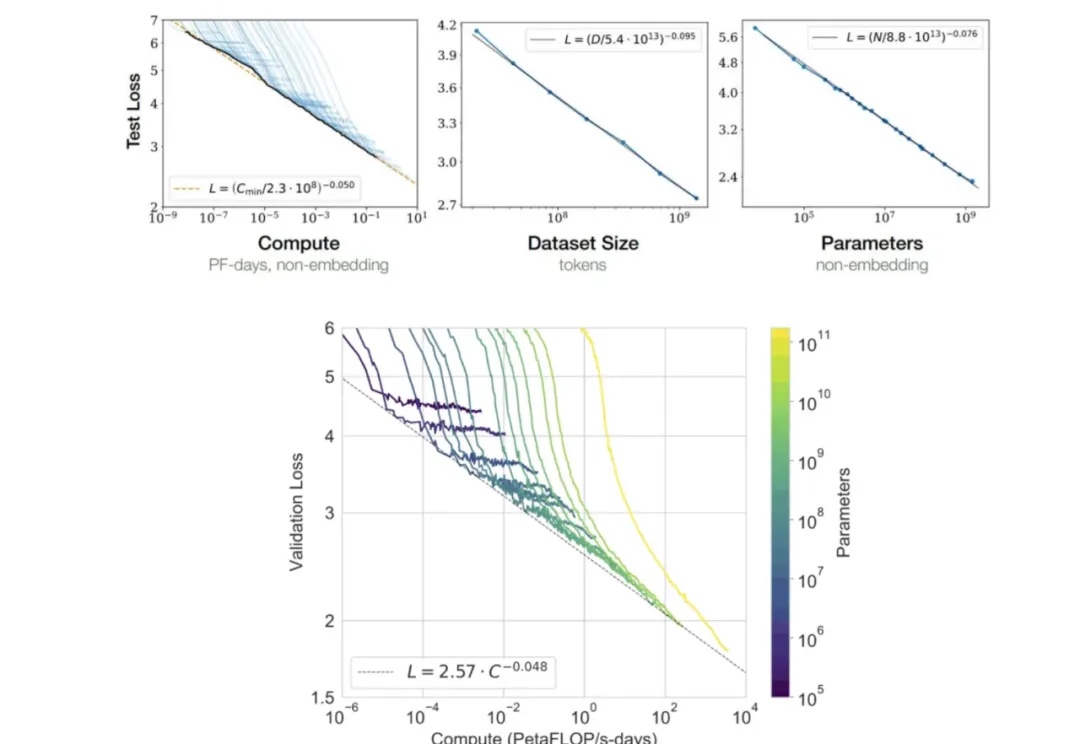
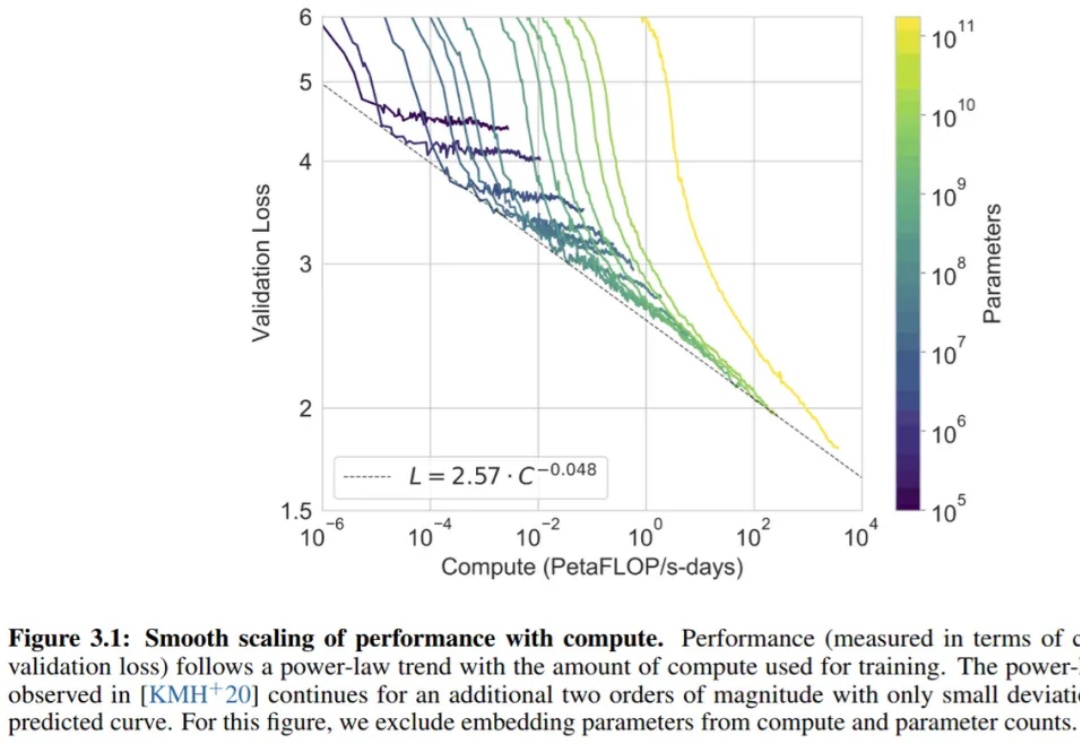
自回归方法,在图像生成中观察到了 Scaling Law。 「Scaling Law 撞墙了?」这恐怕是 AI 社区最近讨论热度最高的话题。

Scaling Law撞墙了吗?OpenAI高级研究副总裁Mark Chen正式驳斥了这一观点。他表示,OpenAI已经有o系列和GPT系列两个模型,来让模型继续保持Scaling。

11 月 23 日,香港科技大学举行了今年度的学位颁授典礼。英伟达创始人和 CEO 黄仁勋又新增一个荣誉工程学博士头衔,与他一同获得荣誉博士学位的还有著名影星梁朝伟、2013 年诺贝尔化学奖得主 Michael Levitt、菲尔兹奖得主 David Mumford。
Claude 3.5 Sonnet 应该是目前公认综合能力最好的基础模型。

Scaling Law撞墙,扩展语言智能体的推理时计算实在太难了!破局之道,竟是使用LLM作为世界模型?OSU华人团队发现,使用GPT-4o作为世界模型来支持复杂环境中的规划,潜力巨大。
Powerful AI 预计会在 2026 年实现,足够强大的 AI 也能够将把一个世纪的科研进展压缩到 5-10 年实现(“Compressed 21st Century”),在他和 Lex Fridman 的最新对谈中,Dario 具体解释了自己对于 Powerful AI 可能带来的机会的理解,以及 scaling law、RL、Compute Use 等模型训练和产品的细节进行了分享

在2024年的AI领域,我们正在见证一个有趣的转折。 OpenAI的进展节奏明显放缓,GPT-5迟迟未能问世,“Scaling Law”成了天方夜谭,即便是年初震撼业界的视频生成模型Sora,也未能如期实现“全面开放”的承诺。